What Data Drift Really Means in Manufacturing and Why It’s Harder Than You Think

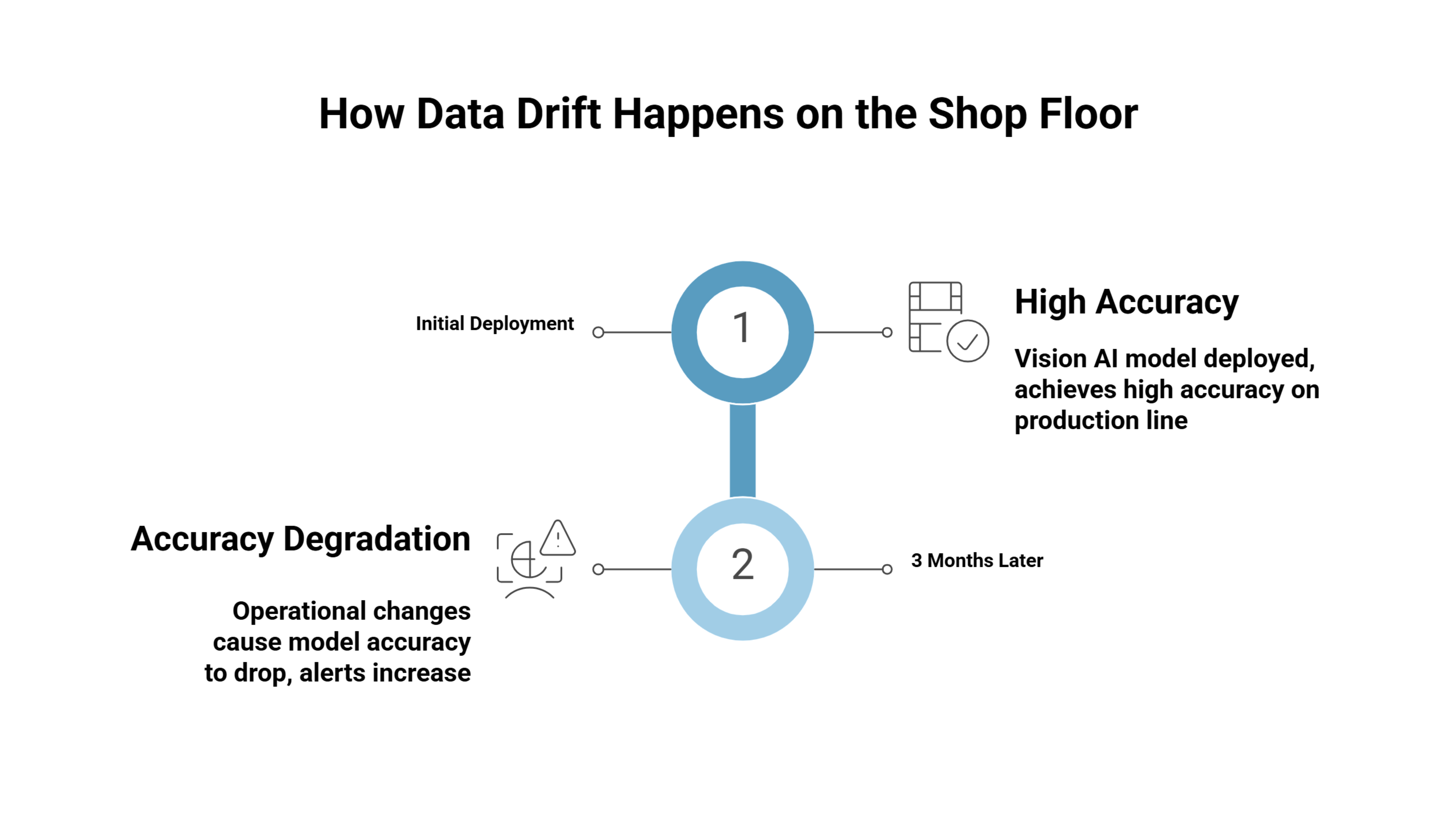
There is a common pattern in manufacturing AI projects. A vision system is installed, tested, and approved. For the first few weeks, it performs well. It detects defects accurately, counts inventory correctly, and tracks safety compliance without issues. Confidence builds quickly.
Then, a few months later, accuracy drops. False positives increase. The system starts missing obvious defects or flagging normal processes as violations. The engineering team checks the code and finds nothing broken. Cameras are clean. Lighting appears unchanged. This pattern is common in systems that perform well during controlled trials but struggle once exposed to real production variability. We’ve explored this gap between pilot success and shop-floor reality in more detail in our post on AI systems that work in pilots but fail after deployment.
The issue is rarely the core technology. The factory floor has moved on, but the model has not. This is data drift in manufacturing, and it is often mistaken for a technical failure when it is actually an operational one. Factories are living environments. Procedures shift, materials vary, and logistics adapt daily to meet production targets.
When a model is trained, it captures a snapshot of how the process looked at that moment in time. It learns patterns based on specific lighting conditions, material batches, operator behaviors, and workflow sequences. But manufacturing rarely stands still long enough for that snapshot to remain accurate. Small, continuous adjustments begin to accumulate, and over time the live environment no longer matches the environment the model was trained on. The gap between expectation and reality widens quietly until performance degradation becomes visible on the shop floor.
When these realities collide with rigid models, we begin to see vision AI model degradation. To understand why this happens and why simple fixes fail, it helps to look at how drift shows up in real operations.
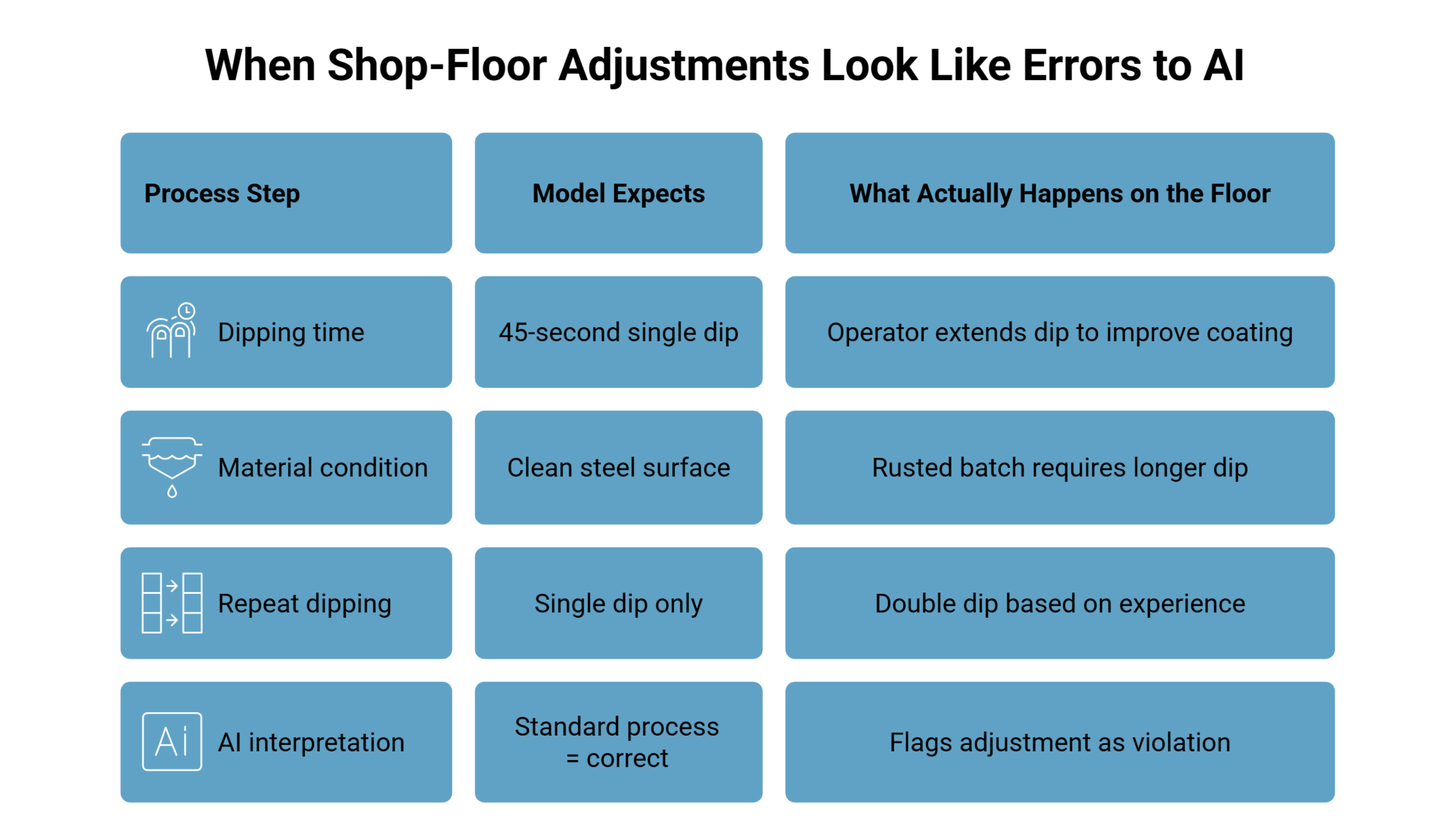
Galvanization: When Operators Override the Model
Consider a vision system installed over a galvanization line to monitor dipping time for quality control. The model is trained on standard operating procedure: material is lowered into the zinc bath, held for 45 seconds, then lifted.
If the system sees a 60-second dip or a double dip, it flags a violation.
Drift appears when operator judgment enters the process. An experienced operator might notice a batch of steel with surface rust or detect colder ambient conditions affecting adhesion. Based on years of experience, they may leave the material in the bath slightly longer or dip it twice to ensure coating quality.
To the operator, this is a routine adjustment. To the model, it looks like a process error. Alerts are triggered repeatedly. If this continues, the plant manager stops trusting the system. The definition of “correct behavior” has shifted based on context the model cannot see.
This is not a bug. It is a production line data change driven by real-time decision-making. Without context, the system treats necessary adjustments as violations, and confidence in the AI erodes.
Furnace Operations: The Hidden Ingredient
Furnaces introduce another subtle source of drift. Vision systems often monitor flame color, slag levels, or combustion intensity to infer temperature stability or material quality. These models assume input material remains consistent.
In reality, supply chains and production recipes change frequently. A metallurgist may introduce a different scrap mix or alloy to meet a specific order. The furnace still operates correctly, but the visual signature shifts. Flame hue changes slightly. Smoke density varies. Slag behavior looks different.
The AI detects unfamiliar visual patterns and predicts temperature imbalance or contamination. Operators check physical sensors, confirm everything is stable, and mute the alert. Over time, alerts lose credibility.
The model has not failed technically. The physical process evolved in ways that were not present in the training data. This is another example of data drift in manufacturing caused by material variation rather than mechanical change.
Weighbridge and Yard Logistics: When Flow Changes
Drift is not limited to production lines. It also appears in plant logistics. Vision systems at weighbridges often handle license plate recognition, vehicle classification, or safety checks. These systems rely on predictable traffic flow and camera angles.
A yard manager dealing with congestion might temporarily reverse a lane to clear a backlog. Suddenly, trucks approach from a different direction. Cameras now see trailer backs instead of cab fronts. Or a new logistics partner introduces flatbed trucks instead of container trucks.
The station’s setup changed to solve an operational problem, but the model still expects the original flow. New angles, vehicle types, and behaviors appear. Accuracy drops immediately. This kind of vision AI model degradation is driven by operational flexibility rather than system failure.
Why Retraining Isn’t a Silver Bullet
The typical response to drift is retraining. Collect new data, label it, update the model. In manufacturing environments, this approach has serious retraining limitations in manufacturing AI.
First, retraining is slow. By the time engineers capture footage of a temporary process adjustment, label it, and deploy an updated model, that specific condition may already be gone. The next shift may return to normal operation. The updated model could now accept behavior that should once again be flagged.
Second, the sources of drift are effectively endless. Lighting changes, raw materials vary, logistics routes shift, and operators adjust processes. Attempting to retrain for every scenario becomes a continuous cycle with no stable endpoint.
Operational changes happen in minutes. Model updates take days or weeks. This mismatch is why many vision deployments struggle to scale beyond pilot programs.
Toward Operational Awareness
Addressing drift requires more than stronger models or faster retraining pipelines. It requires systems that understand context. Instead of treating every deviation as an error, vision systems need a way to capture why a change happened and adapt in step with operations.
Many of these shifts come from changes across people, machines, materials, and methods. When those change, the visual signals change too. We’ve explored how monitoring these operational variables affects AI reliability in our post on monitoring operational changes across production lines.
The goal isn’t to eliminate variation. It’s to keep AI aligned with it. That means building systems that can handle controlled deviations and reflect the real rhythm of the shop floor, rather than forcing operations to match a static model.
If you’re noticing accuracy drop over time or finding that teams stop trusting alerts, it may be worth looking at whether drift is being treated as a technical issue instead of an operational one. If this is happening in your plant, you can share your use case with our team here.
Data drift doesn’t mean the system is broken. It usually means the factory is active, adjusting, and doing what it needs to maintain output and quality. The real challenge is making sure vision systems can move at the same pace as the production environment they’re meant to support.

What Data Drift Really Means in Manufacturing and Why It’s Harder Than You Think